SQL函数(二)

SQL GROUP BY 语句
TIP
GROUP BY 语句可结合一些聚合函数来使用
1 GRIUP BY 语句
GROUP BY 语句用于结合聚合函数,根据一个或多个列堆结果集进行分组。
SQL GROUP BY 语法
SELECT column_name,aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GR
2 演示数据库
Websites表
+----+--------------+---------------------------+-------+---------+
| id | name | url | alexa | country |
+----+--------------+---------------------------+-------+---------+
| 1 | Google | https://www.google.cm/ | 1 | USA |
| 2 | 淘宝 | https://www.taobao.com/ | 13 | CN |
| 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN |
| 4 | 微博 | http://weibo.com/ | 20 | CN |
| 5 | Facebook | https://www.facebook.com/ | 3 | USA |
| 6 | 百度 | https://www.baidu.com/ | 4 | CN |
| 7 | stackoverflow | http://stackoverflow.com/ | 0 | IND |
+----+---------------+---------------------------+-------+---------+
access_log表
mysql> SELECT * FROM access_log;
+-----+---------+-------+------------+
| aid | site_id | count | date |
+-----+---------+-------+------------+
| 1 | 1 | 45 | 2016-05-10 |
| 2 | 3 | 100 | 2016-05-13 |
| 3 | 1 | 230 | 2016-05-14 |
| 4 | 2 | 10 | 2016-05-14 |
| 5 | 5 | 205 | 2016-05-14 |
| 6 | 4 | 13 | 2016-05-15 |
| 7 | 3 | 220 | 2016-05-15 |
| 8 | 5 | 545 | 2016-05-16 |
| 9 | 3 | 201 | 2016-05-17 |
+-----+---------+-------+------------+
9 rows in set (0.00 sec)
3 GROUP BY 简单应用
统计 access_log 各个 site_id 的访问量:
实例:
SELECT site_id,SUM(access_log.count) AS nums
FROM access_log GROUP BY site_id;
执行输出结果:

4 SQL GROUP BY 多表连接
下面的 SQL 语句统计有记录的网站的记录数量:
实例:
SELECT Websites.name,COUNT(access_log.aid) AS nums FROM access_log
LEFT JOIN Websites
ON access_log.site_id=Websites.id
GROUP BY Websites.name;
执行输出结果:

SQL HAVING 子句
TIP
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
1 SQL HAVING 语法
SELECT column1,aggregate_function(column2)
FROM table_name
GROUP BY column1
HAVING condition;
参数说明:
column1:要检索的列aggregate_function(column2):一个聚合函数,例如 SUM、COUNT、AVG 等,应用与 column2 的值table_name:要从中检索数据的表。GROUP BY column1:根据 column1 列的值对数据进行分组HAVING condition:一个条件,用于筛选分组的结果。只有满足条件的分组会包含在结果集中。
2 演示数据库
Websites表
+----+--------------+---------------------------+-------+---------+
| id | name | url | alexa | country |
+----+--------------+---------------------------+-------+---------+
| 1 | Google | https://www.google.cm/ | 1 | USA |
| 2 | 淘宝 | https://www.taobao.com/ | 13 | CN |
| 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN |
| 4 | 微博 | http://weibo.com/ | 20 | CN |
| 5 | Facebook | https://www.facebook.com/ | 3 | USA |
| 6 | 百度 | https://www.baidu.com/ | 4 | CN |
| 7 | stackoverflow | http://stackoverflow.com/ | 0 | IND |
+----+---------------+---------------------------+-------+---------+
access_log表
mysql> SELECT * FROM access_log;
+-----+---------+-------+------------+
| aid | site_id | count | date |
+-----+---------+-------+------------+
| 1 | 1 | 45 | 2016-05-10 |
| 2 | 3 | 100 | 2016-05-13 |
| 3 | 1 | 230 | 2016-05-14 |
| 4 | 2 | 10 | 2016-05-14 |
| 5 | 5 | 205 | 2016-05-14 |
| 6 | 4 | 13 | 2016-05-15 |
| 7 | 3 | 220 | 2016-05-15 |
| 8 | 5 | 545 | 2016-05-16 |
| 9 | 3 | 201 | 2016-05-17 |
+-----+---------+-------+------------+
9 rows in set (0.00 sec)
3 SQLHAVING 实例
① 现在我们要查找总访问量大于 200 的网站。
实例:
SELECT Websites.name,Websites.url,SUM(access_log.count) AS nums
FROM (access_log INNER JOIN Websites ON access_log.site_id=Websites.id)
GROUP BY Websites.name
HAVING SUM(access_log.count) > 200;
执行输出结果:

② 现在我们想要查找访问量大于 200 的网站,并且 alexa 排名小于 200。
我们在 SQL 语句中增加一个普通的 WHERE 子句:
实例:
SELECT Websites.name,SUM(access_log.count) AS nums FROM Websites
INNER JOIN access_log
ON Websites.id=access.log.site_id
WHERE Websites.alexa < 200
GROUP BY Websites.name
HAVING SUM(access_log.count) > 200;
执行输出结果:

SQL EXISTS 运算符
1 EXISTS 运算符
EXISTS 运算符用于判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 false。
SQL EXISTS 语法
SELECT column_name(s)
FROM table_name
WHERE EXISTS
(SELECT column_name FROM table_name WHERE condition);
2 演示数据库
Websites表
+----+--------------+---------------------------+-------+---------+
| id | name | url | alexa | country |
+----+--------------+---------------------------+-------+---------+
| 1 | Google | https://www.google.cm/ | 1 | USA |
| 2 | 淘宝 | https://www.taobao.com/ | 13 | CN |
| 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN |
| 4 | 微博 | http://weibo.com/ | 20 | CN |
| 5 | Facebook | https://www.facebook.com/ | 3 | USA |
+----+---------------+---------------------------+-------+---------+
access_log表
mysql> SELECT * FROM access_log;
+-----+---------+-------+------------+
| aid | site_id | count | date |
+-----+---------+-------+------------+
| 1 | 1 | 45 | 2016-05-10 |
| 2 | 3 | 100 | 2016-05-13 |
| 3 | 1 | 230 | 2016-05-14 |
| 4 | 2 | 10 | 2016-05-14 |
| 5 | 5 | 205 | 2016-05-14 |
| 6 | 4 | 13 | 2016-05-15 |
| 7 | 3 | 220 | 2016-05-15 |
| 8 | 5 | 545 | 2016-05-16 |
| 9 | 3 | 201 | 2016-05-17 |
+-----+---------+-------+------------+
9 rows in set (0.00 sec)
3 SQL EXISTS 实例
① 现在我们想要查找总访问量(count 字段)大于 200 的网站是否存在。
实例:
SELECT Websites.name,Websites.url
FROM Websites
WHERE EXISTS (SELECT count FROM access_log WHERE Websites.id = access_log.site.id AND count > 200);
执行输出结果:

② EXISTS 可以与 NOT 一同使用,查找出不符合查询语句的记录:
实例:
SELECT Websites.name,Websites.url
FROM Websites
WHERE NOT EXISTS (SELECT count access_log WHERE Websites.id = access_log.site_id AND count > 200);
执行输出结果:

SQL UCASE() 函数
TIP
UCASE() 函数把字段的值换位大写。
1 SQL UCASE 语法
SELECT UCASE(column_name) FROM table_name;
用于 SQL Server 的语法
SELECT UPPER(column_name) FROM table_name;
2 演示数据库
Websites表
+----+--------------+---------------------------+-------+---------+
| id | name | url | alexa | country |
+----+--------------+---------------------------+-------+---------+
| 1 | Google | https://www.google.cm/ | 1 | USA |
| 2 | 淘宝 | https://www.taobao.com/ | 13 | CN |
| 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN |
| 4 | 微博 | http://weibo.com/ | 20 | CN |
| 5 | Facebook | https://www.facebook.com/ | 3 | USA |
| 7 | stackoverflow | http://stackoverflow.com/ | 0 | IND |
+----+---------------+---------------------------+-------+---------+
3 SQL UCASE() 实例
下面的 SQL 语句从 Websites 表中选取 name 和 url 列,并把 name 列的值转换为大写:
实例:
SELECT UCASE(name) AS site_title,url
FROM Websites;
执行输出结果:

SQL LCASE() 函数
TIP
LCASE() 函数把字段的值转换为小写。
1 SQL LCASE() 语法
SELECT LCASE(column_name) FROM table_name;
用于 SQL Server 的语法
SELECT LOWER(column_name) FROM table_name;
2 演示数据库
Websites表
+----+--------------+---------------------------+-------+---------+
| id | name | url | alexa | country |
+----+--------------+---------------------------+-------+---------+
| 1 | Google | https://www.google.cm/ | 1 | USA |
| 2 | 淘宝 | https://www.taobao.com/ | 13 | CN |
| 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN |
| 4 | 微博 | http://weibo.com/ | 20 | CN |
| 5 | Facebook | https://www.facebook.com/ | 3 | USA |
| 7 | stackoverflow | http://stackoverflow.com/ | 0 | IND |
+----+---------------+---------------------------+-------+---------+
3 SQL LCASE() 实例
下面的 SQL 语句从 Websites 表中选取 name 和 url 列,并把 name 列的值转换为小写:
实例:
SELECT LCASE(name) AS site_title,url
FROM Websites;
执行输出结果:

SQL MID() 函数
TIP
MID() 函数用于从文本字段提取字符。
1 SQL MID() 语法
SELECT MID(column_name[,start,length]) FROM table_name;
| 参数 | 描述 |
|---|---|
| column_name | 必需。要提取字符的字段。 |
| start | 必需。规定开始位置(起始值是 1)。 |
| length | 可选。要返回的字符数。如果省略,则 MID() 函数返回剩余文本。 |
2 演示数据库
Websites表
+----+--------------+---------------------------+-------+---------+
| id | name | url | alexa | country |
+----+--------------+---------------------------+-------+---------+
| 1 | Google | https://www.google.cm/ | 1 | USA |
| 2 | 淘宝 | https://www.taobao.com/ | 13 | CN |
| 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN |
| 4 | 微博 | http://weibo.com/ | 20 | CN |
| 5 | Facebook | https://www.facebook.com/ | 3 | USA |
| 7 | stackoverflow | http://stackoverflow.com/ | 0 | IND |
+----+---------------+---------------------------+-------+---------+
3 SQL MID() 实例
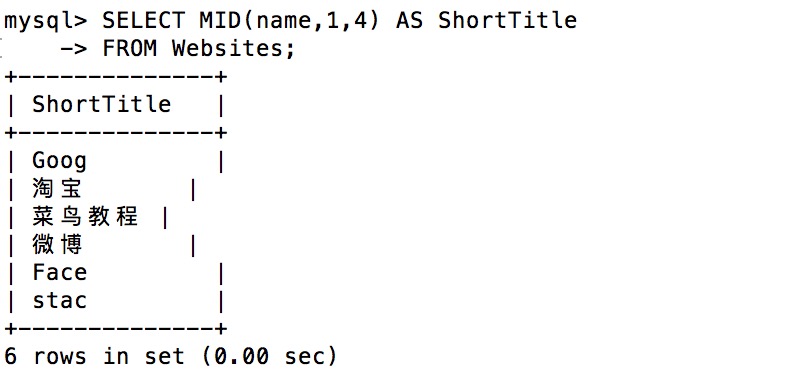
下面的 SQL 语句从 Websites 表的 name 列中提取前 4 个字符:
实例:
SELECT MID(name,1,4) AS ShortTitle
FROM Websites;
执行输出结果: